Excel-kalkylblad innehåller ofta celldisplayer för att förenkla och / eller standardisera datainmatning. Dessa listrutor skapas med hjälp av datavalideringsfunktionen för att ange en lista över tillåtna poster.
För att ställa in en enkel rullgardinslista, välj den cell där data kommer att matas in och klicka sedan på Datavalidering (på fliken Data ), välj Datavalidering, välj Lista (under Tillåt :) och ange listobjekten (separerade med kommatecken ) i fältet Källa : (se figur 1).
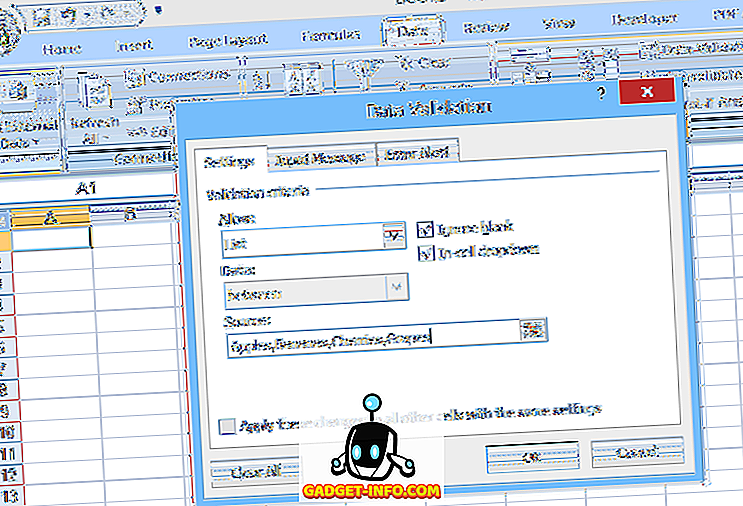
I den här typen av grundläggande rullgardinsmeny anges listan över tillåtna poster i själva datavalideringen. För att göra ändringar i listan måste användaren därför öppna och redigera datavalideringen. Detta kan dock vara svårt för oerfarna användare, eller i fall där listan över val är lång.
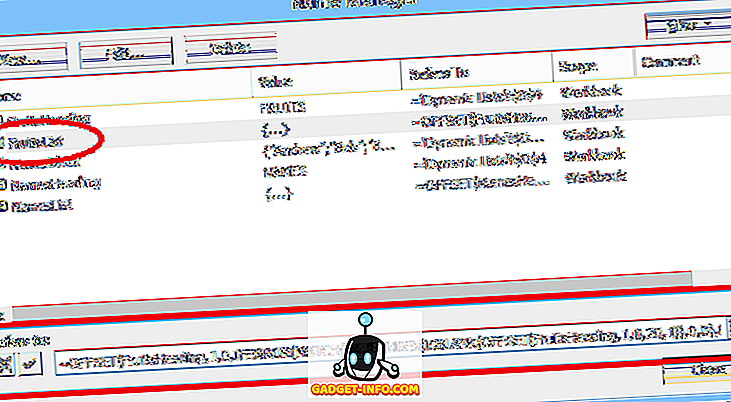
Ett annat alternativ är att placera listan i ett namngivna område inom kalkylbladet och ange sedan det aktuella intervallnamnet (prefaced med ett likformat) i fältet Källa : för datavalidering (som visas i Figur 2).
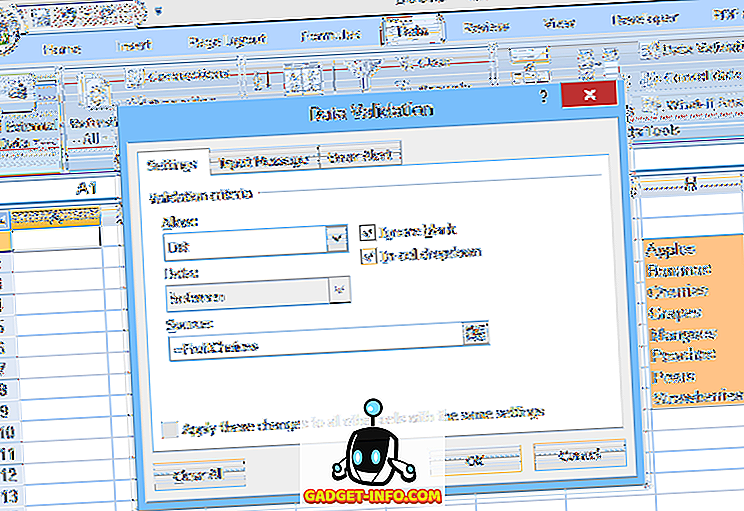
Denna andra metod gör det enklare att redigera valen i listan, men att lägga till eller ta bort objekt kan vara problematisk. Eftersom det angivna intervallet (FruitChoices, i vårt exempel) hänvisar till ett fast antal celler ($ H $ 3: $ H $ 10 som visas), om fler valmöjligheter läggs till cellerna H11 eller nedan kommer de inte dyka upp i rullgardinsmenyn (eftersom dessa celler inte ingår i FruitChoices-sortimentet).
På samma sätt om päron- och jordgubentillförseln t ex raderas kommer de inte längre att visas i rullgardinsmenyn, men i rullgardinsmenyn kommer i stället att innehålla två "tomma" val eftersom nedrullningen fortfarande refererar till hela FruitChoices-sortimentet, inklusive de tomma cellerna H9 och H10.
Av dessa skäl måste det angivna intervallet redigeras för att inkludera fler eller färre celler om de läggs till eller raderas från listan när man använder ett normalt namngivna område som listkälla för en nedrullning.
En lösning på detta problem är att använda ett dynamiskt intervallnamn som källa för dropdown-valen. Ett dynamiskt intervallnamn är en som automatiskt expanderar (eller kontrakt) för att exakt matcha storleken på ett block av data när uppgifter läggs till eller tas bort. För att göra detta använder du en formel, i stället för ett fast antal celladresser, för att definiera det angivna intervallet.
Så här ställer du in ett dynamiskt område i Excel
Ett normalt (statiskt) intervallnamn avser ett specificerat cellområde ($ H $ 3: $ H $ 10 i vårt exempel, se nedan):
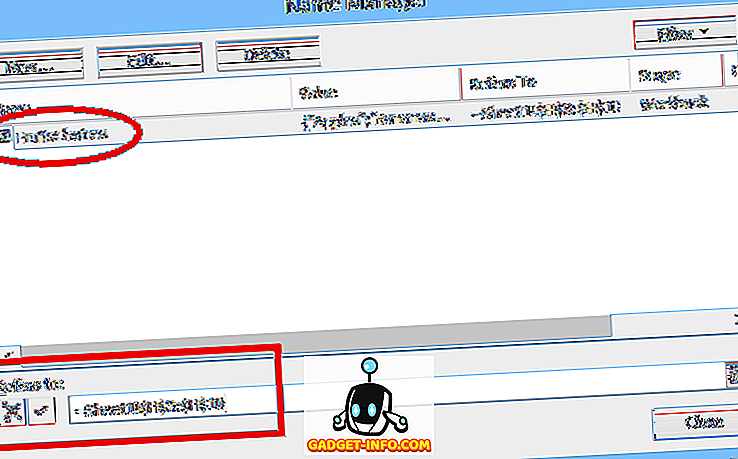
Men ett dynamiskt intervall definieras med hjälp av en formel (se nedan, taget från ett separat kalkylblad som använder dynamiska intervallnamn):
Innan vi börjar, se till att du hämtar vår Excel-exempelfil (sortera makron har blivit inaktiverade).
Låt oss undersöka denna formel i detalj. Valet för Frukter ligger i ett block av celler direkt under en rubrik ( FRUKTER ). Den rubriken tilldelas också ett namn: FruitsHeading :
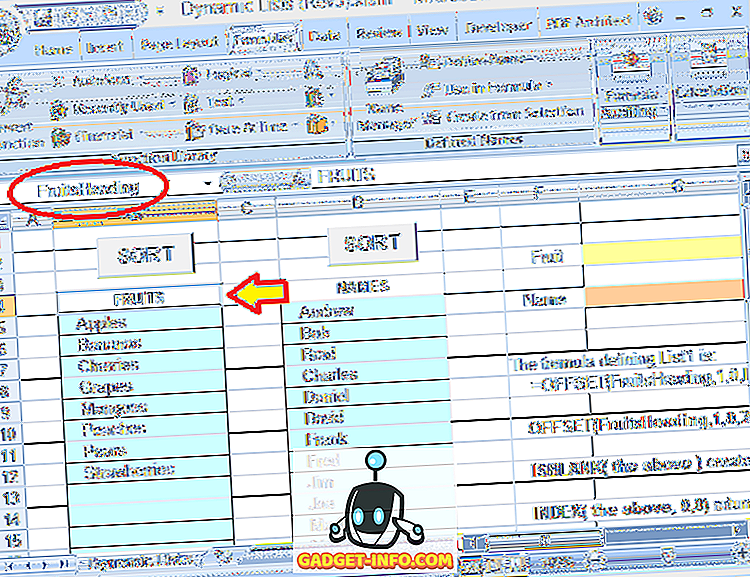
Hela formeln som används för att definiera det dynamiska området för Fruits val är:
= OFFSET (FruitsHeading, 1, 0, OMFEL (MATCH (TRUE, INDEX (ISBLANK (FÖRSKJUTNING (FruitsHeading, 1, 0, 20, 1)), 0, 0), 0) -1, 20), 1)
FruitsHeading hänvisar till rubriken som är en rad ovanför den första posten i listan. Numret 20 (används två gånger i formeln) är den maximala storleken (antal rader) för listan (det kan justeras efter önskemål).
Observera att i det här exemplet finns det bara 8 poster i listan, men det finns också tomma celler under dessa där ytterligare poster kan läggas till. Numret 20 hänvisar till hela blocket där poster kan göras, inte till det faktiska antalet poster.
Låt oss nu bryta ner formeln i bitar (färgkodning varje del), för att förstå hur det fungerar:
= OFFSET (FruitHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( OFFSET (FruitsHeading, 1, 0, 20, 1) ), 0, 0), 0) -1, 20), 1)
Den "innersta" delen är OFFSET (FruitsHeading, 1, 0, 20, 1) . Detta refererar till blocket med 20 celler (under FruitsHeading-cellen) där val kan anges. Denna OFFSET-funktion säger i grunden: Börja på FruitsHeading- cellen, gå ner 1 rad och över 0 kolumner, välj sedan ett område som är 20 rader långt och 1 kolumn bred. Så det ger oss det 20-radiga blocket där Fruits-valen anges.
Nästa del av formeln är ISBLANK- funktionen:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX ( ISBLANK (ovanstående), 0, 0), 0) -1, 20), 1)
Här har OFFSET-funktionen (förklarad ovan) ersatts med "ovanstående" (för att göra det enklare att läsa). Men ISBLANK-funktionen fungerar på 20-radiga celler som OFFSET-funktionen definierar.
ISBLANK skapar sedan en uppsättning med 20 TRUE och FALSE värden, vilket indikerar om var och en av de enskilda cellerna i 20-radsintervallet som refereras av OFFSET-funktionen är tom (tom) eller ej. I det här exemplet kommer de första 8 värdena i uppsättningen att vara FALSE eftersom de första 8 cellerna inte är tomma och de sista 12 värdena kommer att vara TRUE.
Nästa del av formeln är INDEX-funktionen:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ovanstående, 0, 0), 0) -1, 20), 1)
Återigen hänvisar "ovan" till de ovan beskrivna ISBLANK- och OFFSET-funktionerna. INDEX-funktionen returnerar en array som innehåller de 20 TRUE / FALSE-värdena som skapats av ISBLANK-funktionen.
INDEX används normalt för att välja ett visst värde (eller värdeintervall) ur ett datablock, genom att ange en viss rad och kolumn (inom det här blocket). Men inställningen av rad- och kolumninmatningar till noll (som görs här) orsakar INDEX att returnera en array som innehåller hela datablocket.
Nästa del av formeln är MATCH-funktionen:
= OFFSET (FruitsHeading, 1, 0, IFERROR ( MATCH (TRUE, ovan, 0) -1, 20), 1)
MATCH- funktionen returnerar läget för det första TRUE-värdet, inom den matris som returneras av INDEX-funktionen. Eftersom de 8 första inmatningarna i listan inte är tomma kommer de 8 första värdena i fältet att vara FALSKT, och det nionde värdet blir SANT (eftersom den 9: e raden i intervallet är tom).
Så kommer MATCH-funktionen att returnera värdet på 9 . I det här fallet vill vi verkligen veta hur många poster som finns i listan, så formeln subtraherar 1 från MATCH-värdet (vilket ger läget för den sista posten). Så slutligen returnerar MATCH (TRUE, above, 0) -1 värdet på 8 .
Nästa del av formeln är IFERROR-funktionen:
= OFFSET (FruitsHeading, 1, 0, IFERROR (ovan, 20), 1)
IFERROR-funktionen returnerar ett alternativt värde, om det angivna första värdet resulterar i ett fel. Denna funktion är inkluderad eftersom, om hela blocket av celler (alla 20 rader) är fyllda med poster, kommer MATCH-funktionen att returnera ett fel.
Detta beror på att vi berättar MATCH-funktionen för att leta efter det första TRUE-värdet (i arrayen av värden från ISBLANK-funktionen), men om ingen av cellerna är tomma kommer hela matrisen att fyllas med felaktiga värden. Om MATCH inte kan hitta målvärdet (TRUE) i array som det söker, returnerar det ett fel.
Så om hela listan är full (och därför returnerar MATCH ett fel), returnerar IFERROR-funktionen istället värdet på 20 (vet att det måste finnas 20 poster i listan).
Slutligen returnerar OFFSET (FruitsHeading, 1, 0, ovan, 1) det område vi letar efter: Börja på FruitsHeading-cellen, gå ner 1 rad och över 0 kolumner, välj sedan ett område som dock är många rader långt ifrån Det finns poster i listan (och 1 kolumn bred). Så hela formuläret kommer tillsammans att returnera intervallet som bara innehåller de faktiska inmatningarna (ner till den första tomma cellen).
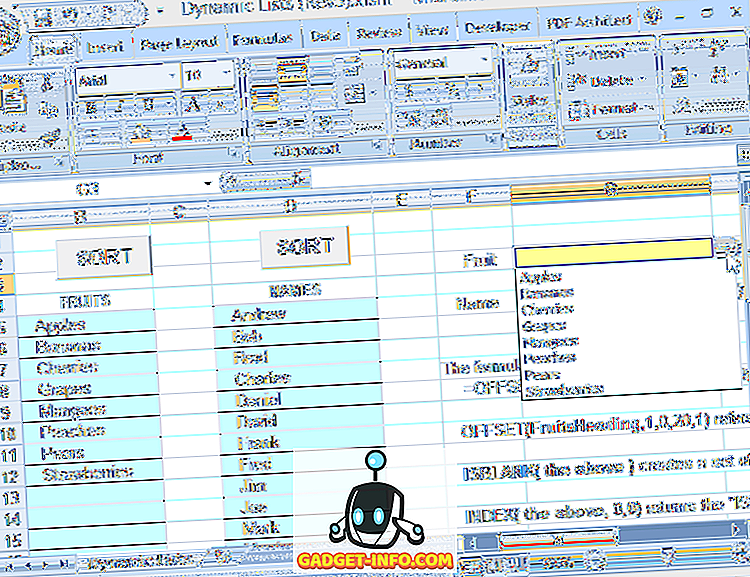
Med hjälp av denna formel för att definiera det intervall som är källan till rullgardinsmenyn kan du fritt redigera listan (lägga till eller ta bort poster, så länge som de återstående posterna börjar på den övre cellen och är sammanhängande) och rullgardinsmenyn kommer alltid att återspegla strömmen lista (se figur 6).
Exempelfilen (Dynamiska Listor) som används här är inkluderad och kan hämtas från den här webbplatsen. Makronen fungerar dock inte eftersom WordPress inte gillar Excel-böcker med makron i dem.
Som ett alternativ för att ange antalet rader i listblocket kan listblocket tilldelas sitt eget radnamn, som sedan kan användas i en modifierad formel. I exempelfilen använder en andra lista (Namn) den här metoden. Här tilldelas hela listblocket (under rubriken "NAMES", 40 rader i exempelfilen) namnet på namnet NameBlock . Den alternativa formeln för att definiera namnlisten är då:
= OFFSET (NamesHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( NamesBlock ), 0, 0), 0) -1, ROWS (NamesBlock) ), 1)
där NamesBlock ersätter OFFSET (FruitsHeading, 1, 0, 20, 1) och ROWS (NamesBlock) ersätter 20 (antal rader) i tidigare formel.
Så, för dropdown listor som enkelt kan redigeras (inklusive andra användare som kan vara oerfarna), försök använda dynamiska radnamn! Och notera att, även om den här artikeln har fokuserats på listrutor, kan dynamiska radnamn användas var som helst du behöver för att referera till ett intervall eller en lista som kan variera i storlek. Njut av!